How ZK verified tasks secure AI data
ZK verified tasks solve the privacy-trust trade-off in AI training. They allow labelers to prove they completed a task correctly without exposing the underlying data. This mechanism ensures data privacy while maintaining high-quality training sets.
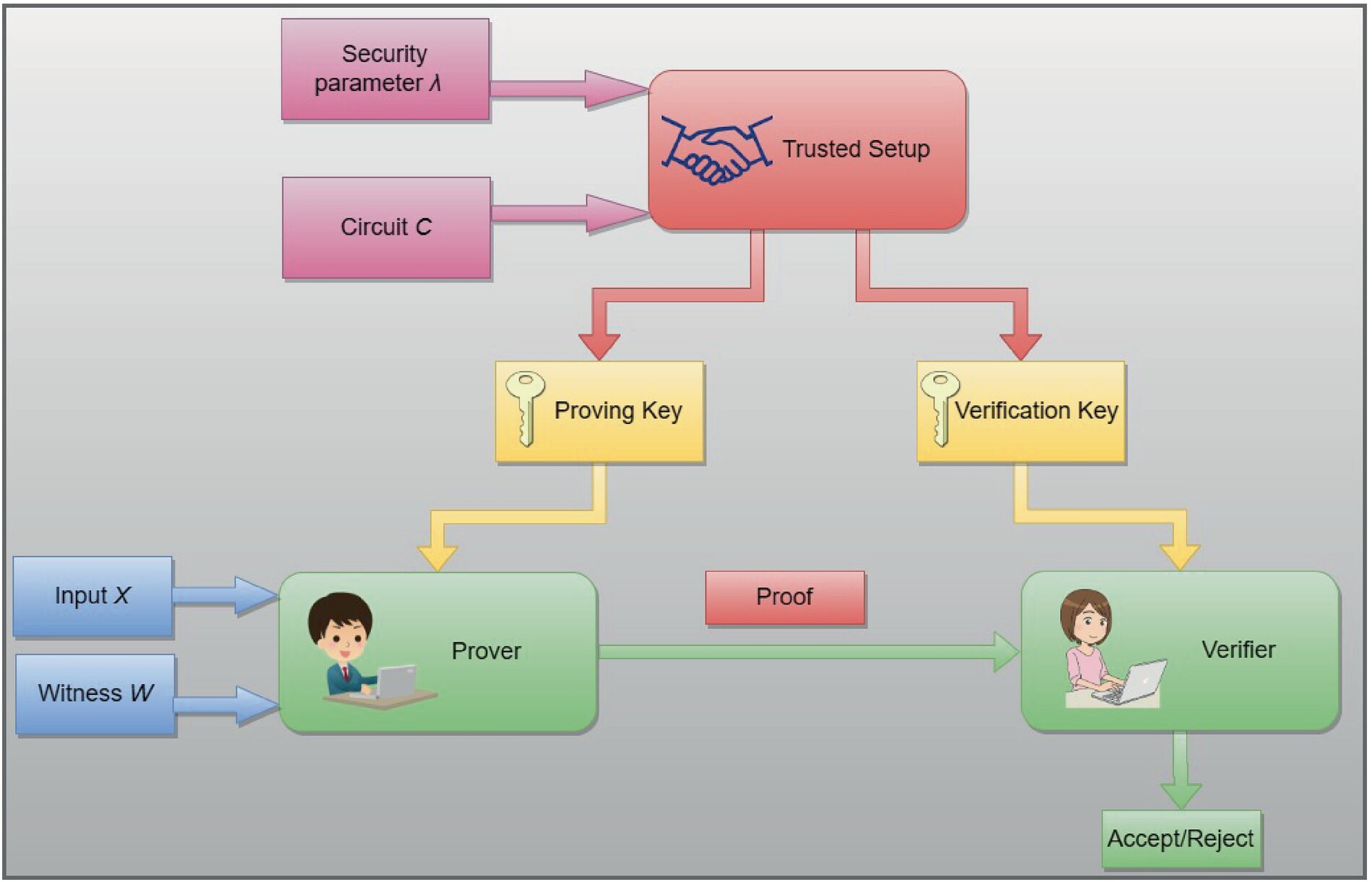
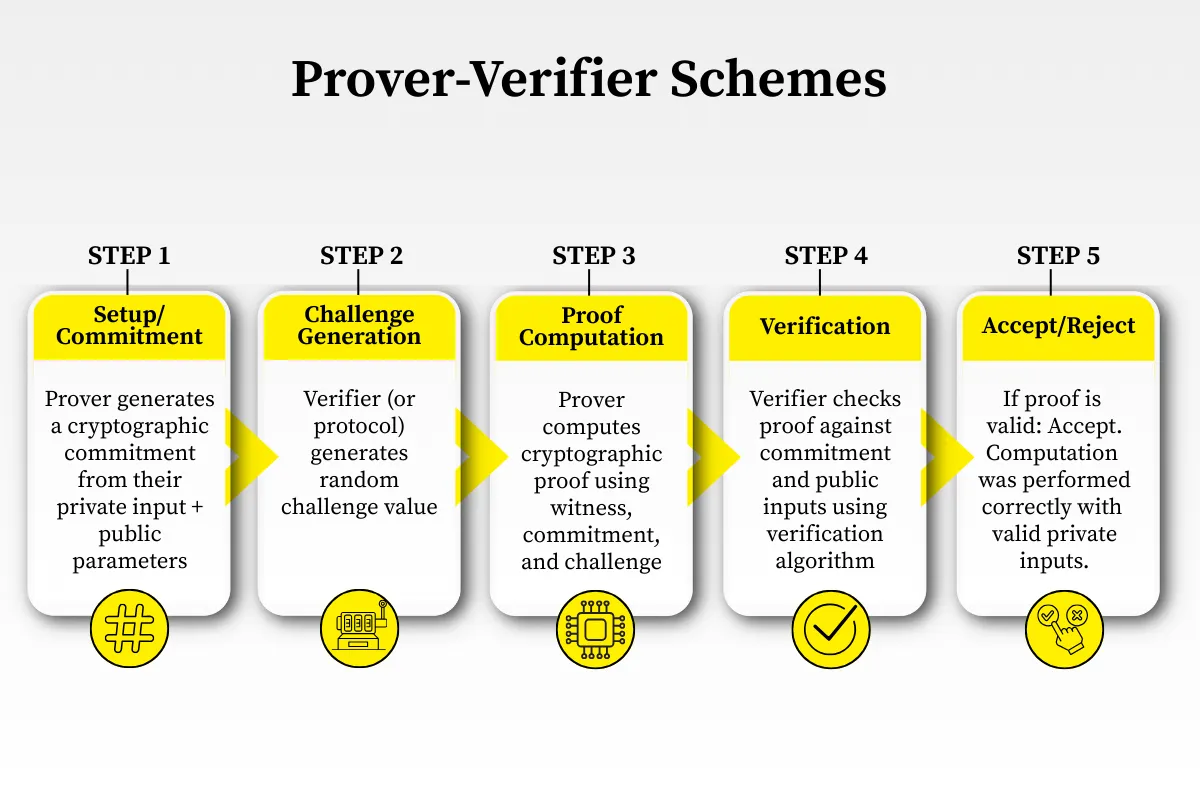
The process follows a strict sequence. Labelers submit work, which generates a cryptographic proof. The network verifies this proof instantly. This allows AI companies to trust the data without seeing the raw content.
The task sequence
- Submission: A labeler annotates data and submits it to the network.
- Proof Generation: The system creates a zero-knowledge proof of the annotation.
- Verification: The network checks the proof mathematically.
- Validation: Correct tasks are approved; incorrect ones are rejected.
Why this matters
Traditional data labeling requires sharing raw data, creating privacy risks. ZK verified tasks remove this risk. Labelers prove correctness without revealing inputs. This enables secure, scalable AI training.
Troubleshooting common issues
- Proof failures: Check data formatting before submission.
- Verification delays: Ensure network congestion is minimal.
- Invalid proofs: Review annotation guidelines for accuracy.
Step-by-step: Submitting a verified task
The workflow for submitting a ZK verified task follows a strict sequence: receive, label, prove, and submit. This process ensures that data labeling remains private while guaranteeing accuracy on-chain. The following steps outline the standard procedure for developers and labelers integrating with zkVerify or similar verification layers.
1. Receive encrypted task assignment
Your workflow begins when the task distributor sends an encrypted task payload. This payload contains the raw data requiring labeling and the specific schema for the output. Because the data is encrypted, you cannot see the underlying information until you decrypt it locally using your secure enclave or designated key. This step ensures that sensitive training data never leaves your controlled environment in plaintext.
2. Label data locally
Once decrypted, you perform the labeling task within your local environment. This might involve bounding boxes for images, sentiment tags for text, or classification labels for audio. The critical constraint here is that all processing happens off-chain. You are not uploading the raw data to a central server; you are only preparing the labeled output locally. This isolation is what preserves the privacy of the source material.
3. Generate ZK proof of label accuracy
After labeling, you must generate a zero-knowledge proof that confirms your work was done correctly according to the task rules. Using a proving system like zkVerify, you create a cryptographic statement that attests to the validity of your labels without revealing the labels themselves or the underlying data. This proof serves as a mathematical guarantee that the task was completed as specified, eliminating the need for manual auditing.
The workflow begins when the task distributor sends an encrypted task payload. This payload contains the raw data requiring labeling and the specific schema for the output. Because the data is encrypted, you cannot see the underlying information until you decrypt it locally using your secure enclave or designated key. This step ensures that sensitive training data never leaves your controlled environment in plaintext.
Once decrypted, you perform the labeling task within your local environment. This might involve bounding boxes for images, sentiment tags for text, or classification labels for audio. The critical constraint here is that all processing happens off-chain. You are not uploading the raw data to a central server; you are only preparing the labeled output locally. This isolation is what preserves the privacy of the source material.

After labeling, you must generate a zero-knowledge proof that confirms your work was done correctly according to the task rules. Using a proving system like zkVerify, you create a cryptographic statement that attests to the validity of your labels without revealing the labels themselves or the underlying data. This proof serves as a mathematical guarantee that the task was completed as specified, eliminating the need for manual auditing.
Finally, you submit the generated proof to the on-chain verifier contract. The contract validates the proof against the task parameters. If the proof is valid, the contract records the successful completion and triggers any associated rewards or token distributions. The raw data and labels remain hidden, but the integrity of the training dataset is now cryptographically secured.
4. Submit proof to verifier contract
The final step involves broadcasting the generated proof to the blockchain via a verifier contract. The contract checks the proof against the public parameters of the task. If the proof is valid, the transaction is confirmed, and the labeler receives their reward. The raw data and labels remain hidden, but the integrity of the training dataset is now cryptographically secured.
This sequence transforms data labeling from a trust-based service into a verifiable computation. By relying on ZK proofs, projects can scale their AI training pipelines without compromising user privacy or data security.
ZK verified tasks vs. traditional labeling platforms
Traditional data labeling platforms operate like centralized factories. You upload raw data, the platform’s internal team or contracted workers label it, and you receive a clean dataset back. This model relies on trust: you must believe the platform didn’t leak your data, didn’t introduce labeling errors, and didn’t tamper with the results. ZK verified tasks flip this dynamic. Instead of trusting the labeler or the platform, you trust mathematics. The ZK proof acts as a cryptographic receipt, confirming the work was done correctly without revealing the underlying data or the labeler’s identity.
The comparison below highlights how these two approaches differ across the four metrics that matter most for AI training pipelines: privacy, verification cost, trust model, and scalability.
| Feature | Traditional Labeling | ZK Verified Tasks |
|---|---|---|
| Data Privacy | High risk of exposure; data resides on central servers | Zero-knowledge; inputs never revealed to verifiers |
| Verification Cost | Low upfront cost; high audit overhead later | Higher upfront compute cost; near-zero audit cost |
| Trust Model | Trust the platform’s internal controls | Trustless; trust the cryptographic proof |
| Scalability | Limited by human labor supply | Limited by blockchain throughput and proof generation |
Privacy and Data Sovereignty
In traditional labeling, your proprietary data—whether medical records, financial transactions, or user behavior logs—must be visible to the labelers. Even with NDAs, the data exists in plaintext on the platform’s servers. This creates a significant attack surface. If the platform is compromised, your data is gone.
ZK verified tasks solve this by keeping the data encrypted or hidden. The labelers (or AI agents) perform the labeling on encrypted data or within a secure enclave. The resulting ZK proof verifies that the labeling logic was applied correctly without ever exposing the raw data to the verifier. As noted by Delphi Digital, ZKPs provide a "mathematically sound way to verify the correctness of computations without revealing the inputs or intermediate steps" [[src-serp-1]]. This means you can outsource labeling to a global, anonymous workforce without risking data leakage.
Verification Cost and Speed
Traditional platforms are cheap to start. You pay per label or per hour. However, the cost of verification is hidden. If you suspect errors, you must hire third-party auditors to spot-check the dataset, which is slow and expensive.
ZK verification shifts the cost structure. Generating a zero-knowledge proof is computationally intensive and currently more expensive per task than a human click. However, once the proof is generated, verification is instantaneous and nearly free. This makes ZK ideal for high-volume, repetitive tasks where the cost of a single error is high. Space and Time notes that ZK proofs can verify off-chain data accuracy "without sacrificing" the integrity of the query results [[src-serp-3]]. You trade higher upfront compute costs for the elimination of post-hoc auditing.
Trust Model and Auditability
Traditional platforms rely on a "trust us" model. You review their quality assurance processes, but you cannot independently verify every single label without re-labeling the data yourself. This creates an information asymmetry where the platform knows more about the data quality than you do.
ZK verified tasks are trustless. The proof is public and verifiable by anyone. If a label is submitted, the ZK proof accompanies it. Any downstream consumer of the AI model can verify that the label was generated by a valid worker using the correct logic, without needing to know who the worker is or what the data contained. This creates a transparent, immutable audit trail that traditional platforms simply cannot provide.
Scalability and Labor
Traditional labeling scales linearly with human labor. To label 1 million images, you need thousands of humans. This is slow, inconsistent, and difficult to manage at global scale. Quality control becomes a bottleneck.
ZK verified tasks can scale with compute power. While proof generation is slower than a human click, it is consistent and can be parallelized. As ZK hardware accelerators improve, the speed gap narrows. More importantly, ZK allows for "proof-of-humanity" or "proof-of-work" mechanisms that can integrate AI-assisted labeling with human verification in a way that is both scalable and secure, avoiding the fatigue and inconsistency of pure human labeling.
Common pitfalls in ZK proof generation
Building ZK verified tasks for AI data labeling sounds straightforward in theory, but the gap between a working circuit and a deployed, verifiable task is where most projects stall. The primary friction points are proof generation time and circuit complexity. If you do not account for these early, your AI training pipeline will face bottlenecks that negate the benefits of trustless verification.
The most frequent failure mode is underestimating the computational cost of the prover. A circuit that works on a small dataset can become unmanageable when scaled to millions of labeled images or text entries. Proof generation is not just a mathematical operation; it is a heavy computational load. If your circuit constraints are too loose or your logic is not parallelized, the time to generate a proof can stretch from seconds to hours, making real-time or near-real-time labeling impossible.
Another common trap is circuit complexity. Every additional constraint in your zk-circuit increases the size of the proof and the time required to generate it. For AI data labeling, this often happens when developers try to include too much validation logic in the on-chain or verifiable layer. It is better to keep the circuit focused on the core verification of the label’s integrity and move secondary checks to off-chain or pre-processing stages.
Tip: Optimize your circuit constraints early. Large datasets can slow down proof generation significantly if not parallelized.
To navigate these hurdles, you need a systematic approach to debugging and optimization. The following steps outline how to identify and resolve common proof generation failures before they impact your deployment.
Start by reviewing your circuit’s constraint count. High constraint counts directly correlate with slower proof generation. Use profiling tools to identify which gates are consuming the most resources. Simplify complex logic into simpler arithmetic constraints where possible to reduce the proof size and generation time.
Do not generate proofs for large datasets sequentially. Break your AI labeling tasks into smaller, independent chunks. Parallelize the proof generation process across multiple workers or nodes. This approach distributes the computational load and ensures that your pipeline can handle the volume of data required for robust AI training.
Never deploy a circuit based solely on small test cases. Use a representative sample of your actual AI labeling data to stress-test the proof generation. This reveals edge cases and performance bottlenecks that only appear with real-world data complexity. Ensure your prover can handle the worst-case scenario within your acceptable time limits.
By focusing on these technical fundamentals, you can avoid the common pitfalls that derail ZK projects. The goal is not just to generate a proof, but to generate one efficiently and reliably. This ensures that your AI data labeling process remains both secure and scalable.
Tools and platforms for ZK verified tasks
Implementing ZK verified tasks requires a stack that separates proof generation from proof verification. The infrastructure landscape includes specialized verifiers like zkVerify, which offers rapid and inexpensive proof verification for developers building dApps. For data integrity, platforms like Space and Time use zk proofs to verify off-chain query results, ensuring that AI training data hasn't been tampered with.
To build these systems, developers typically start with a ZK framework such as Circom or Halo2 to define the circuit. Once the circuit is set, a verification key is generated to validate submissions on-chain. Testing this flow on a testnet before mainnet deployment is critical to avoid costly errors.
-
Select ZK framework (e.g., Circom, Halo2)
-
Define verification key
-
Test on testnet
Frequently asked questions about ZK proofs
Zero-knowledge proofs (ZKPs) are cryptographic protocols that allow one party to prove a statement is true without revealing the underlying data. In the context of AI data labeling, this means a model can verify that training data was processed correctly without seeing the raw, sensitive information.
No comments yet. Be the first to share your thoughts!