What ZK verified tasks actually do
ZK verified tasks use zero-knowledge proofs to confirm that data labeling was performed correctly without exposing the raw data or the labeler’s identity. This approach has become the 2026 standard for trustless AI training because it solves the fundamental tension between data privacy and model reliability.
In traditional training pipelines, verifying label quality often requires sharing the underlying data, which creates security risks. With ZK verified tasks, a prover (the labeling agent) generates a cryptographic proof that the labeling rules were followed. A verifier checks this proof to confirm validity. The verifier learns only that the task was completed correctly, not the data itself or who performed the work.
This architecture decouples verification from visibility. AI models can be trained on datasets where the provenance and accuracy are mathematically guaranteed, yet the sensitive information remains opaque to everyone except the original data owners. The result is a trust layer that scales with the dataset size, rather than degrading as more participants join the training process.

Step 1: Define the verification circuit
Before any data enters the training pipeline, you must establish the rules of the game. A ZK verified task is only as trustworthy as the circuit that validates it. This circuit acts as a digital gatekeeper, determining exactly what constitutes a "valid" label or task result before it is accepted by the AI model.
Think of the circuit as a strict filter. It takes raw, untrusted inputs—such as image annotations, text classifications, or sensor readings—and applies cryptographic logic to prove they meet your specific criteria. If the input fails to match the defined logic, the circuit produces no proof, and the task is rejected. This ensures that your AI training data is free from noise, bias, or malicious manipulation.
To build this circuit, you need to define three core components:
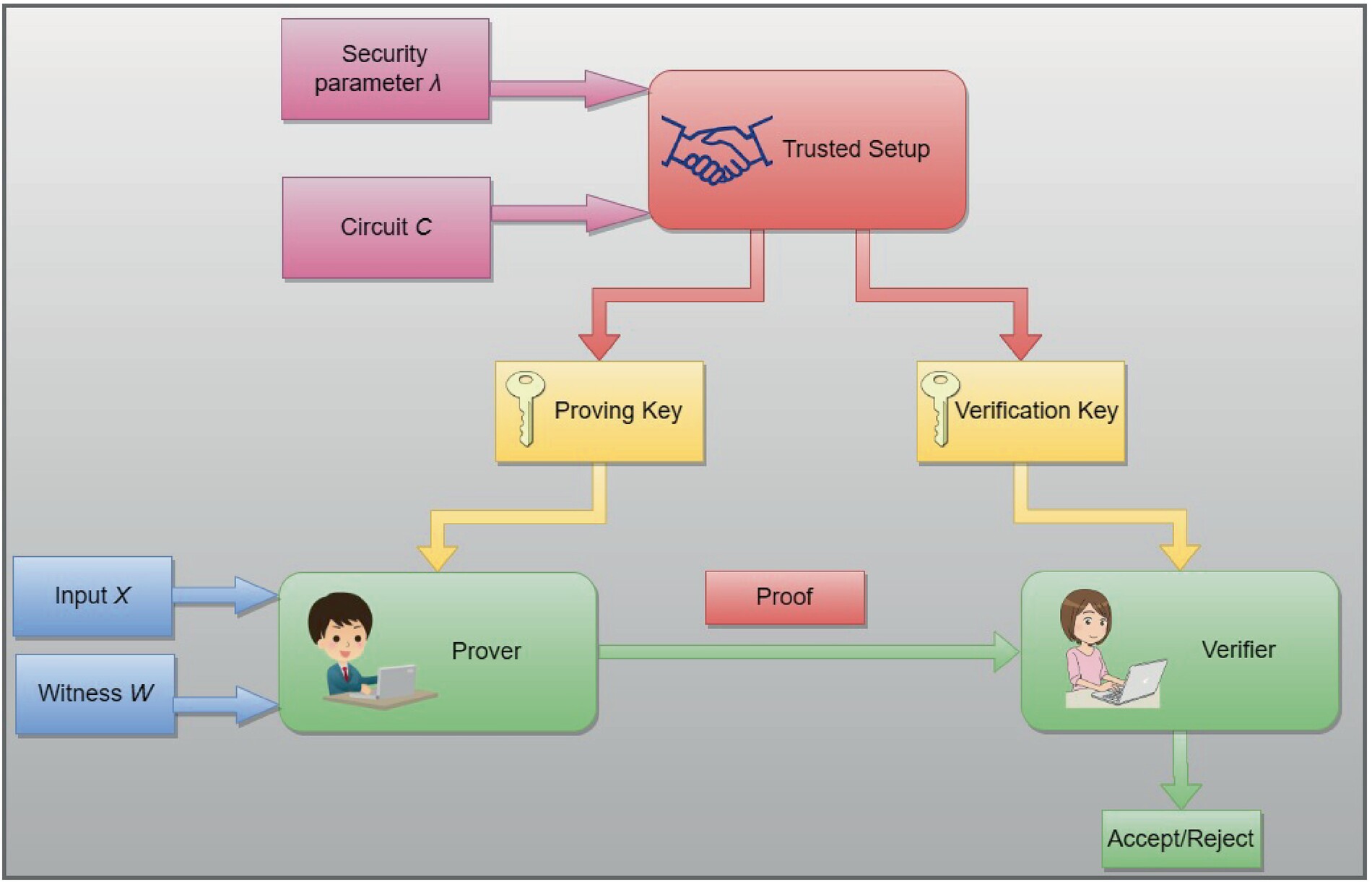
Define the exact shape and type of data the circuit will accept. For example, if you are verifying image labels, specify that the input must be a 224x224 pixel JPEG with a valid hash. These constraints prevent malformed or malicious data from entering the proof system.
Write the business logic that determines validity. This is where you encode your domain expertise. If you are verifying sentiment analysis, the circuit might check that the output label matches a predefined set of allowed categories. This logic is translated into arithmetic constraints that the ZK solver can understand.
Once the logic is satisfied, the circuit generates a succinct cryptographic proof. This proof is small enough to verify on-chain or by a lightweight verifier, but it mathematically guarantees that the input data met all your constraints without revealing the raw data itself.
This process transforms subjective human judgments into objective, verifiable facts. By locking your validation logic into a circuit, you create a trustless environment where AI trainers can collaborate without needing to trust each other’s integrity.
-
Define input data types and formats
-
Encode domain-specific validation rules as arithmetic constraints
-
Test circuit with known valid and invalid inputs
-
Generate and verify a sample proof
Generate proofs off-chain
The verification phase is where ZK verified tasks deliver their primary advantage: privacy and cost reduction. When a worker completes a task, the heavy cryptographic lifting happens locally on their machine, not on the blockchain. This off-chain execution ensures that the raw data remains private while still producing a mathematical guarantee of correctness.
The execution workflow
Workers run the designated AI training tasks using their local resources. Once the computation is complete, the worker generates a zero-knowledge proof. This proof is a compact cryptographic snippet that attests to the correct execution of the task without revealing the underlying data or the worker's identity. The process typically involves compiling the task logic into a circuit and running a prover to generate the proof file.
Convert the AI training task into a mathematical circuit. This step defines the constraints that the proof must satisfy, ensuring that the output is valid according to the predefined rules. The circuit acts as the blueprint for the cryptographic verification.
Execute the prover software on the worker's local machine. The prover uses the circuit and the task data to generate the proof. This is the most computationally intensive part of the process, but it happens entirely off-chain, keeping gas costs low.
Once the proof is generated, the worker submits it to the on-chain verifier contract. The contract checks the proof against the circuit's public inputs. If the proof is valid, the task is marked as complete, and the worker is rewarded. The raw data never touches the blockchain.
Why off-chain matters
Verification on a blockchain virtual machine is expensive. Even relatively simple tasks can incur significant gas fees if performed on-chain. By generating proofs off-chain, you shift the computational burden away from the network. This approach allows for more complex AI training tasks to be verified at a fraction of the cost, making trustless AI training economically viable.
Step three: Verify on the blockchain
The final stage of building ZK verified tasks is submitting the compact proof to a smart contract. This step transforms a mathematical assertion into an immutable, on-chain record. By verifying the proof directly on the blockchain, you ensure that the AI training data has been processed according to the agreed-upon rules without revealing the underlying data itself.
Computation on a standard blockchain virtual machine is expensive. Verifying a complex ZK proof natively on Ethereum or similar L1s can cost hundreds of dollars per transaction. This is why most developers use specialized verification layers like zkVerify. These networks act as dedicated bridges, offering rapid and inexpensive proof verification. They handle the heavy lifting of validating the cryptographic logic, allowing your dApp to interact with the main chain at a fraction of the cost.
When you submit your ZK verified tasks, the smart contract checks the proof's validity against the public parameters. If the proof holds, the contract updates the state—perhaps releasing funds to a worker or marking a dataset as "verified." This creates a trustless audit trail. Anyone can inspect the blockchain to confirm that the work was done correctly, without needing to trust the original prover.

Before submitting, ensure your proof generator has produced a verification key compatible with your target smart contract. This key defines the mathematical constraints that the proof must satisfy. Mismatched keys will cause verification to fail immediately on-chain.
Call the verification function on your smart contract, passing the proof data and public inputs. If you are using a verification layer like zkVerify, you may send the proof to their gateway first, which then relays the verified result to your contract. This two-step process significantly reduces gas fees for the end user.
Once the transaction is mined, the blockchain state reflects the verification. Check the event logs to ensure the "Verified" flag was set correctly. This on-chain record is now permanent and can be used by other contracts or frontends to trigger downstream actions, such as rewarding workers or unlocking data access.
This verification step closes the loop on trustless AI training. By anchoring the ZK verified tasks to the blockchain, you create a system where integrity is guaranteed by code, not by reputation. The cost of verification becomes negligible compared to the value of the trust established.
Comparing ZK tasks to traditional labeling
Traditional data labeling operates like a centralized factory. An organization hires a vendor, sends raw data to a private server, and waits for tagged outputs. This model is simple but introduces significant friction: you must trust the vendor not to leak sensitive information, and the cost scales linearly with the volume of data.
ZK verified tasks shift this dynamic by moving verification to the edge. Instead of trusting a central authority to process data, the system uses zero-knowledge proofs to mathematically guarantee that the labeling was performed correctly without exposing the underlying data. This approach separates the act of labeling from the act of verification, allowing for a more decentralized and privacy-preserving workflow.
The table below breaks down the core differences between these two approaches across privacy, cost, trust, and scalability.
| Feature | Traditional Labeling | ZK Verified Tasks |
|---|---|---|
| Privacy | Data is exposed to the labeling vendor | Data remains private; only proofs are shared |
| Trust Model | Trust in central vendor | Trust in cryptographic proofs |
| Cost Structure | High per-label cost due to labor | Lower marginal cost via automation |
| Scalability | Limited by workforce size | Highly scalable via distributed nodes |
No comments yet. Be the first to share your thoughts!